Aria Synthetic Environments (ASE) Dataset
1 Overview
The Aria Synthetic Environments (ASE) dataset [1] is a large-scale collection of 100,000 unique procedurally-generated indoor scenes with realistic Aria glasses sensor simulations. It serves as the primary training and evaluation dataset for SceneScript and provides valuable data for scene understanding research.
1.1 Links
1.2 Dataset Scale
- 100,000 unique multi-room interior scenes
- 58M+ RGB images captured from egocentric trajectories
- 67 days of total trajectory time
- 7,800 km of total trajectory distance
- ~23 TB total dataset size
- 100 scenes with ground-truth meshes
- appox. 120 MB per mesh
- 1,641 scenes with GT Meshes
- approx. 100MB per scene snippet (20 s @ 10 fps), hence approx. 164 GB for all snippets
1.3 Local ATEK shard snapshot (.data/ase_efm)
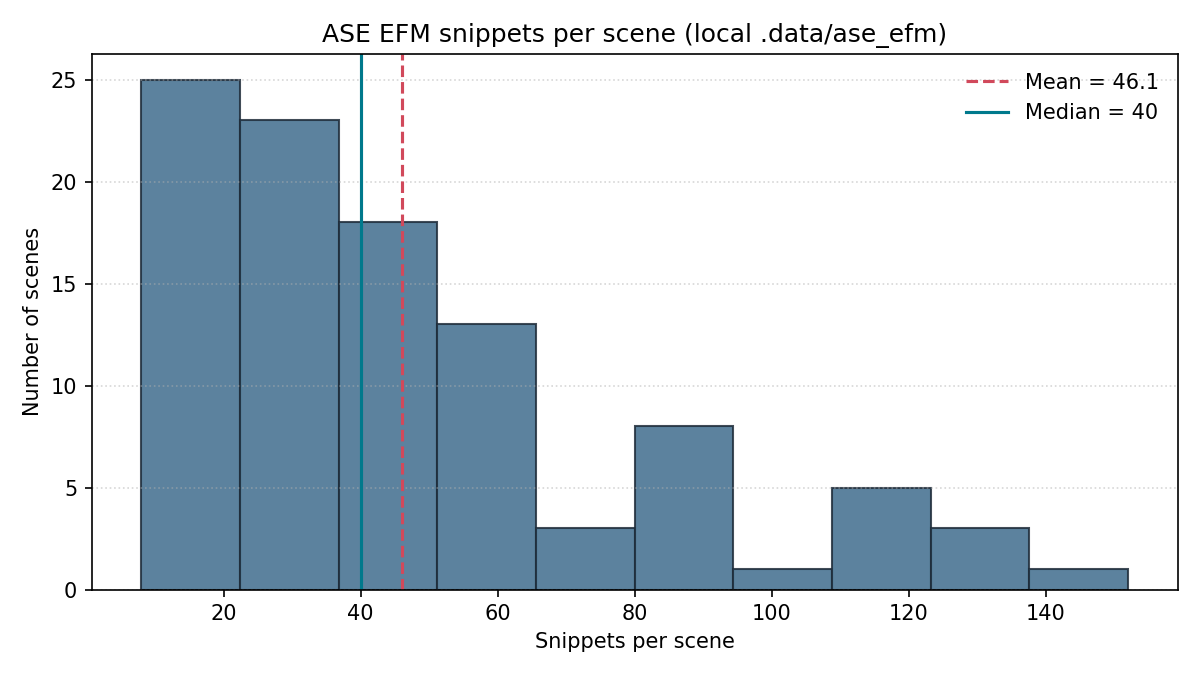
This repo includes a local ASE-ATEK WebDataset snapshot at .data/ase_efm (per-scene folders with multiple shards-*.tar). To estimate snippet counts, each shard is scanned for sequence_name.txt entries (one per snippet), then summed across shards per scene. The histogram below summarizes the per-scene snippet distribution (see Wikipedia :: Histogram). A fresh scan on December 31, 2025 produced:
- Scenes: 100
- Total snippets: 4,608
- Snippets per scene: min 8, p10 8, median 40, mean 46.1, p90 88.8, max 152
- Using avg file size 18.26 MiB → ~82.17 GiB (not including all efm outputs)
- Using avg file size of 305 MiB → ~1.37 TiB including all efm outputs
.data/ase_efm snapshot.1.4 Ground Truth Annotations
1.5 Scene Characteristics
Each scene contains:
- Multi-room layouts: Up to 5 complex Manhattan-world rooms - Scenes composed of axis-aligned walls, floors, and ceilings.
- Egocentric trajectories: ~2-minute walkthroughs per scene
- Realistic sensor simulation: Aria camera and lens characteristics
- Rich object diversity: Furniture, decorations, architectural elements

2 Data Structure
Each scene in the ASE dataset follows a consistent directory structure:
scene_id/
├── ase_scene_language.txt # Ground truth scene layout in SSL format
├── object_instances_to_classes.json # Mapping from instance IDs to semantic classes
├── trajectory.csv # 6DoF camera poses along the egocentric path
├── semidense_points.csv.gz # Semi-dense 3D point cloud from MPS SLAM
├── semidense_observations.csv.gz # Point observations (which images see which points in the PC)
├── rgb/ # RGB image frames
│ ├── 000000.png
│ └── ...
├── depth/ # Ground truth depth maps
│ ├── 000000.png
│ └── ...
└── instances/ # Instance segmentation masks
├── 000000.png
└── ...2.1 Scene Language (ase_scene_language.txt)
The ground truth scene layout encoded in SceneScript’s Structured Scene Language (SSL). Each line represents a primitive with its parameters:
make_wall, id=0, a_x=-2.56, a_y=6.16, a_z=0.0, b_x=5.07, b_y=6.16, b_z=0.0, height=3.26, thickness=0.0
make_door, id=1000, wall0_id=2, wall1_id=4, position_x=-1.51, position_y=1.84, position_z=1.01, width=1.82, height=2.02
make_window, id=2000, wall0_id=0, position_x=4.45, position_y=6.16, position_z=1.64, width=1.01, height=2.12Primitives include:
make_wall: 3D line segments defining room boundariesmake_door: Door positions, dimensions, and wall connectionsmake_window: Window positions and sizesmake_prim: Generic 3D primitives (boxes, cylinders, bezier shapes, …)- Implicitly defines floors and ceilings through wall heights
2.2 Object Instance Mapping (object_instances_to_classes.json)
Maps pixel values in instance segmentation masks to semantic categories:
{
"0": "empty_space",
"1": "background",
"2": "wall",
"18": "bed",
"23": "chair",
"31": "dresser",
"45": "plant_or_flower_pot",
...
}Major object categories:
- Architectural: walls, floors, ceilings, doors, windows
- Furniture: bed, chair, sofa, table, cabinet, dresser, shelf
- Decorations: lamp, mirror, picture_frame, plant, rug
- Utilities: fan, container, clothes_rack
2.3 Trajectory (trajectory.csv)
6DoF camera poses at each frame, aligned with the scene coordinate system:
graph_uid,tracking_timestamp_us,utc_timestamp_ns,tx_world_device,ty_world_device,tz_world_device,qx_world_device,qy_world_device,qz_world_device,qw_world_device
<uuid>,100000,-1,1.234,-0.567,1.650,0.012,0.034,-0.456,0.889
<uuid>,133333,-1,1.245,-0.578,1.651,0.013,0.035,-0.457,0.888
...See MPS Output - Trajectory in the Project Aria documentation for details.
Columns:
graph_uid: Unique identifier for the coordinate frametracking_timestamp_us: Device timestamp in microsecondstx,ty,tz_world_device: 3D translation in metersqx,qy,qz,qw_world_device: Rotation quaternion (Hamilton convention)
2.4 Semi-Dense Point Cloud (semidense_points.csv.gz)
3D points reconstructed from Project Aria Machine Perception Services’ SLAM, representing the scene geometry:
uid,graph_uid,px_world,py_world,pz_world,inv_dist_std,dist_std
12345,<uuid>,1.234,-0.567,2.345,8.130,0.123
12346,<uuid>,1.235,-0.566,2.346,8.065,0.124
...Columns:
uid: Unique point identifiergraph_uid: Coordinate frame identifier, depending on the frame this point was first observed in.px,py,pz_world: 3D coordinates in world frame (meters)inv_dist_std: Inverse of distance standard deviation in [\(m^{-1}\)], measure for the quality of the 3D PCdist_std: Distance standard deviation in meters (depth uncertainty)
Nominal threshold values are a maximum inv_dist_std of 0.005 and a maximum dist_std of 0.01.
2.5 Point Observations (semidense_observations.csv.gz)
Records which camera frames observe which 3D points (visibility information):
uid,frame_tracking_timestamp_us,camera_serial,u,v
12345,100000,<serial>,512.3,384.7
12345,133333,<serial>,515.1,382.9
12346,100000,<serial>,620.8,401.2
...Columns:
uid: Point identifier (ref touidinsemidense_points.csv.gz)frame_tracking_timestamp_us: Frame timestamp in microsecondscamera_serial: Identifier of the camera which observed the pointu,v: Sub-Pixel coordinates in the image frame of the camera that observed the point
Useful for:
- Understanding point visibility across views
- Information about the surfaces in the scene, as well as free space
- Computing information gain for NBV
- Analyzing coverage and redundancy
For further information on both SLAM point clouds and visibility information, see MPS Output - Semi-Dense Point Cloud.
2.6 RGB Images (rgb/*.png)
Simulated Aria camera images (1408×1408 resolution, typical):
- Realistic lens distortion
- Simulated lighting and materials
- Egocentric perspective
2.7 Depth Maps (depth/*.png)
Ground truth depth for each RGB frame (16-bit PNG, metric depth in millimeters):
- Perfect ground truth depth
- Depth values stored as 16-bit integers representing millimeters
- Corresponds 1:1 with RGB pixels
- Metric depth enables direct unprojection to 3D point clouds
- Useful for supervised learning and evaluation
- Can still be used to obtain the oracle RRI to evaluate candidate views
2.8 Instance Segmentation (instances/*.png)
Per-pixel instance labels (16-bit PNG):
- Each pixel value corresponds to an instance ID
- Map IDs to classes using
object_instances_to_classes.json - Enables entity-level analysis
3 Modalities in EVL: Intuition & Math
EVL consumes ASE snippets by projecting every voxel center \(\mathbf{v}\) of a gravity-aligned grid \(\mathcal{V}\) into all observed modalities and concatenating the resulting signals before 3D reasoning.
- Multi-stream images: For each stream \(s \in \{\text{rgb}, \text{slaml}, \text{slamr}\}\) and frame \(f\), calibrated poses \(\mathbf{T}_f^s\) and intrinsics \(\mathbf{K}^s\) project \(\mathbf{v}\) to pixels \(\mathbf{p}^s_f = \pi(\mathbf{K}^s (\mathbf{T}_f^s)^{-1} \mathbf{v})\). DinoV2 features \(\mathbf{F}^s_f(u,v)\) are sampled via bilinear interpolation and aggregated across time/streams by masked means and variances efm3d/model/lifter.py:398.
- Depth & semi-dense points: Distance maps provide metric rays \(\mathbf{x}(u,v) = \mathcal{D}(u,v)\mathbf{K}^{-1}[u,v,1]^\top\), while SLAM points \(\mathbf{P}_t\) with uncertainty (
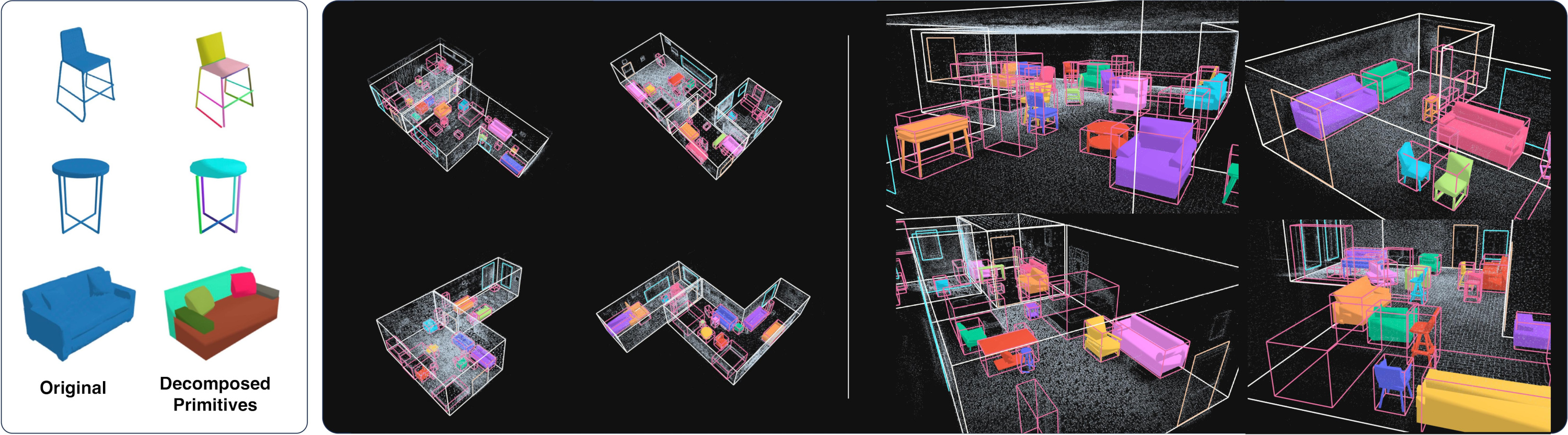
dist_std) voxelize into binary surface masks. Rays traced through measured points mark free-space voxels \(\mathcal{M}_{\text{free}}\) efm3d/model/lifter.py:180 and efm3d/utils/ray.py:179. - OBB supervision: Snippets include oriented boxes stored as 34-channel
ObbTWtensors (obbs/padded_snippet), already expressed in snippet coordinates with per-frame timestamps efm3d/aria/obb.py:97. These supervise centerness, IoU, and class heads during training efm3d/utils/evl_loss.py:120. - Occupancy targets & meshes: Ground-truth meshes \(\mathcal{M}\) or depth samples populate occupancy grids through
pointcloud_to_occupancy_snippet, enabling per-voxel losses efm3d/utils/reconstruction.py:37 and later fusion/evaluation via marching cubes efm3d/inference/fuse.py:187. Note: GT meshes are provided only for 100 validation scenes!
Collectively these channels encode texture, geometry, free space, and semantics—the same ingredients we need for VIN-style RRI prediction on ASE sequences.
4 GT 3D Assets & Annotations
4.1 Oriented Bounding Boxes
- The ASE → EFM adaptor injects
obbs/padded_snippet(shape[T, 128, 34]) plusobbs/sem_id_to_namefor each snippet. Helper methods keep them aligned with the snippet frame efm3d/dataset/efm_model_adaptor.py:480. - Classes follow the 43-category taxonomy shipped with EFM3D; optional remapping via
config/taxonomy/atek_to_efm.csvharmonises ATEK labels. - Access pattern:
batch[ARIA_OBB_PADDED]returns anObbTWwrapper supporting.transform,.bb3_center_world, etc.
4.2 Ground-Truth Meshes
- Validation scenes deliver watertight meshes stored as
scene_ply_{scene_id}.ply(ASE) orgt_mesh.ply(ADT). EVL tooling resolves them viaget_gt_mesh_ply()using the sequence id efm3d/inference/pipeline.py:33. - Meshes are not embedded in the snippet batch; load them on demand for evaluation or to create oracle RRIs. Surface samples feed algorithms like
eval_mesh_to_meshfor Chamfer/F-score computation efm3d/utils/mesh_utils.py:136.
5 EVL Training Format (ATEK WebDataset)
EFM3D trains EVL on ATEK WebDataset (WDS) snippets: 2 s shards (20 frames) are streamed and cropped into overlapping 1 s windows (10 frames) via AtekWdsStreamDataset efm3d/dataset/atek_wds_dataset.py:70. The adaptor enforces fixed shapes and timestamps efm3d/dataset/efm_model_adaptor.py:604.
5.1 ATEK Key Naming Convention
ATEK uses a structured naming scheme for data keys:
Format: <prefix>#<identifier>+<parameter>
Prefixes:
mtd= Motion Trajectory Data (device poses over time)mfcd= Multi-Frame Camera Data (per-frame camera data)msdpd= Multi-Semi-Dense Point Data (SLAM point clouds)
Separators:
#separates prefix from identifier+separates identifier from parameter
Examples:
# Motion trajectory: (T, 3, 4) SE(3) transformation matrices
ts_world_device = sample["mtd#ts_world_device"]
# Camera projection parameters
projection_params = sample["mfcd#camera-rgb+projection_params"]
# Depth images: (T, 1, H, W)
depth_images = sample["mfcd#camera-rgb-depth+images"]
# Semi-dense SLAM points: (N, 3) in world coordinates
points_world = sample["msdpd#points_world+stacked"]5.2 ATEK Data Keys
| Key | Shape | Type | Description |
|---|---|---|---|
rgb/img, slaml/img, slamr/img |
[F, C, H, W] (≈[10, 3/1, 1408, 1408]) |
float32 | Normalized frames per stream. |
rgb/calib, slaml/calib, slamr/calib |
CameraTW | TensorWrapper | Intrinsics/extrinsics replicated across frames. |
rgb/t_snippet_rig, … |
[F, 12] |
PoseTW | Camera poses in snippet frame. |
pose/t_snippet_rig |
[F, 12] |
PoseTW | Rig trajectory used for lifting. |
points/p3s_world |
[F, N, 3] (N≈50 000) |
float32 | Semi-dense SLAM points (NaN padded). |
points/dist_std, points/inv_dist_std |
[F, N, 1] |
float32 | Depth uncertainty per point. |
rgb/distance_m |
[F, 1, H, W] |
float32 | Ray distances from GT depth. |
obbs/padded_snippet |
[F, 128, 34] |
ObbTW | Padded oriented boxes with semantics. |
obbs/sem_id_to_name |
dict | mapping | Semantic lookup table. |
snippet/t_world_snippet |
[1, 12] |
PoseTW | Snippet anchor pose in world frame. |
snippet/time_ns |
[1, 1] |
int64 | Start timestamp for relative times. |
rgb/img/snippet_time_s, … |
[F, 1] |
float32 | Relative timestamps per modality. |
Practical notes.
- Tensor wrappers (
CameraTW,PoseTW,ObbTW) behave like torch tensors while exposing interpolation/transform helpers. points/p3s_worldis already aligned with the snippet frame; invalid slots are NaN so masks can be inferred cheaply.obbs/padded_snippetis present for ASE training snippets; if absent (gt_exists_flag=False) the adaptor skips OBB processing.- Ground-truth meshes stay on disk—resolve them lazily when computing Chamfer/F-score or oracle RRIs.
6 Coordinate Conventions
ASE follows Project Aria’s coordinate conventions:
6.1 World Frame
- Origin: Arbitrary world coordinate origin for each scene
- Axes: Typically Z-up, Manhattan-world aligned
- Units: Meters
In the EFM3D / ATEK preprocessing used in this project, world gravity is always aligned with the VIO convention, i.e. the gravity vector in world coordinates is [0, 0, -g] (pose/gravity_in_world and GRAVITY_DIRECTION_VIO / EFM_GRAVITY_IN_WORLD in efm3d). For ASE and ADT sequences, any dataset-specific gravity (e.g. [0, -g, 0] in ADT) is rotated into this VIO frame before training or evaluation, so +Z is consistently “up” in the world frame we use for RRI and NBV.
6.2 Camera Frames
- Origin: At camera’s optical center
- X-axis: Points right (from camera perspective)
- Y-axis: Points down
- Z-axis: Points forward (optical axis)
EFM3D follows the LUF camera convention (X = Left, Y = Up, Z = Forward) with image origin in the top-left pixel (projection_matrix_rdf_top_left in efm3d.utils.viz). When we construct viewing poses (e.g. NBV candidate views) we always build camera rotations in this same LUF convention and then express them in the Z-up VIO world frame above, so the axes are consistent between ASE, ATEK, EFM3D and our oracle/NBV code.
6.2.1 Using ATEK for ML Workflows
For training and evaluation, use ATEK’s preprocessed datasets and tools:
# Download preprocessed ASE data (PyTorch WebDataset format)
python3 atek/tools/atek_wds_data_downloader.py \
--config-name efm \
--input-json-path ase_ATEK_download_urls.json \
--output-folder-path ./data/ase_atek \
--download-wds-to-local
# Download ground truth meshes for evaluation
python3 atek/tools/ase_mesh_downloader.py \
--input-json-path ase_mesh_download_urls.json \
--output-folder-path ./ase_meshes